In this post, we are going to use PySpark to process xml files to extract the required records, transform them into DataFrame, then write as csv files (or any other format) to the destination. The input and the output of this task looks like below.
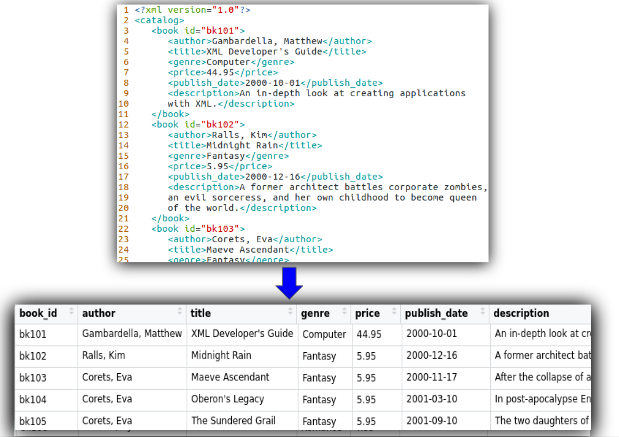
In this post, we are going to use PySpark to process xml files to extract the required records, transform them into DataFrame, then write as csv files (or any other format) to the destination. The input and the output of this task looks like below.
Data Analyst vs Data Engineer vs Data
Scientist Skill Sets
|
||
Data Analyst
|
Data Engineer
|
Data Scientist
|
Data Warehousing
|
Data Warehousing
& ETL
|
Statistical &
Analytical skills
|
Adobe & Google
Analytics
|
Advanced
programming knowledge
|
Data Mining
|
Programming
knowledge
|
Hadoop-based
Analytics
|
Machine Learning
& Deep learning principles
|
Scripting &
Statistical skills
|
In-depth knowledge
of SQL/ database
|
In-depth
programming knowledge (SAS/R/ Python coding)
|
Reporting &
data visualization
|
Data architecture
& pipelining
|
Hadoop-based
analytics
|
SQL/ database
knowledge
|
Machine learning
concept knowledge
|
Data
optimization
|
Spread-Sheet
knowledge
|
Scripting,
reporting & data visualization
|
Decision
making and soft skills
|
{kind=link}