In this post, we are going to use PySpark to process xml files to extract the required records, transform them into DataFrame, then write as csv files (or any other format) to the destination. The input and the output of this task looks like below.
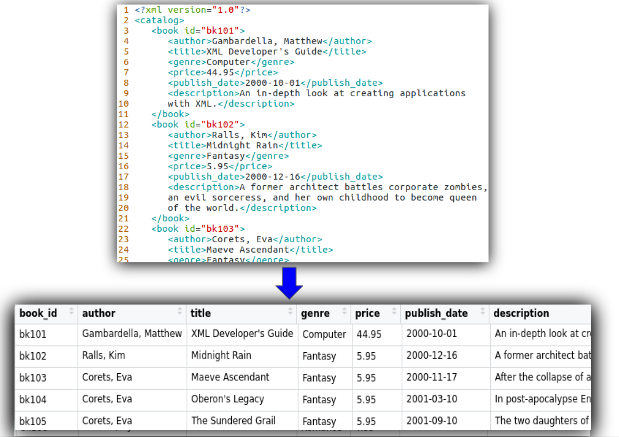
In this post, we are going to use PySpark to process xml files to extract the required records, transform them into DataFrame, then write as csv files (or any other format) to the destination. The input and the output of this task looks like below.